



证券之星数据中心计算显示股票短线杠杆怎么操作,对该股盈利预测较准的分析师团队为东吴证券的马天翼、鲍娴颖。
在日常生活中,我们经常能看到一些有趣的英文单词拼写错误,比如把“mayonnaise”(蛋黄酱)写成“mayonase”。
对于人类来说,这种拼写错误通常不会造成理解障碍,可是对于目前的 AI 语言模型来说,这却是一个不小的挑战。
为了解决这个问题,Meta、美国华盛顿大学和美国芝加哥大学的科学家们共同开发出了一种突破性的新型 AI 架构,取名为字节潜在 Transformer(BLT,Byte Latent Transformer)。
近日,相关论文以《字节潜在 Transformer: 补丁扩展优于 tokens》(Byte Latent Transformer: Patches Scale Better Than Tokens)为题在发表在预印本网站 arXiv 上[1]。
主要作者包括拉姆·帕苏努鲁(Ram Pasunuru)、佩德罗·罗德里格斯(Pedro Rodriguez)、约翰·阮(John Nguyen)、阿里·霍尔茨曼(Ari Holtzman)和斯里尼瓦桑·伊耶(Srinivasan Iyer)。

图丨相关论文(来源:arXiv)
实际上,传统 AI 语言模型的局限性源于它们处理文本的基本方式。
这些模型会把输入的文本切分成一个个预先定义好的 token,这种 tokenization 的方式虽然能提高计算效率,但也让模型失去了对单个字母的精确控制能力。
举个简单的例子,让 AI 数一数“mayonnaise”这个词中有几个字母 n,很多模型都会感到困难。
不仅如此,这种基于固定 token 的方式还会在处理拼写错误、小语种翻译,以及图像、声音等其他类型数据时遇到瓶颈。
值得关注的是,BLT 抛弃了传统的 tokenization 方式,转而直接处理最基础的字节数据。
为了平衡计算效率,BLT 采用了一种动态分组机制:在处理简单、容易预测的文本时,它会将字节组合成较大的数据块。
而在遇到复杂文本时,则会创建较小的数据块并投入更多计算资源。这就像是一个细心的人类阅读者,会根据文章难度调整自己的阅读节奏。
从技术角度来看,BLT 的架构包含三个核心组件,分别是:轻量级的局部编码器、强大的潜在全局 Transformer 和局部解码器。
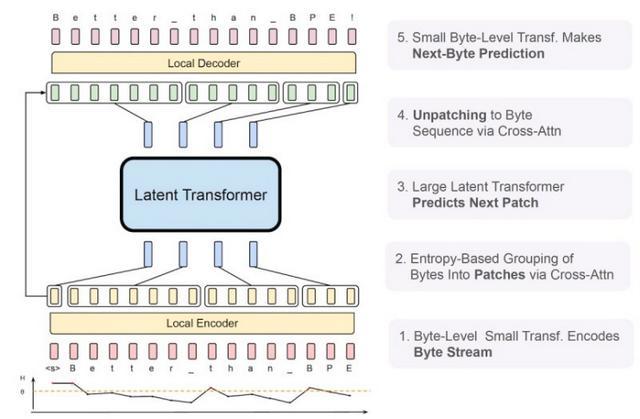
图 | BLT 的架构(来源:Meta)
编码器负责将原始字节序列转换成数据块;全局 Transformer 作为系统的主力,负责处理这些数据块并预测下一个数据块;最后,由解码器将处理后的数据块重新转换为字节序列。
研究团队对媒体表示,这种设计能够让 BLT 既保持高效的处理能力,又不失灵活性。
这种新型架构带来的一个重要优势是,它能够根据数据的复杂度来平衡计算资源的分配。
例如,在预测一个单词的结尾时,由于结果通常比较容易预测,系统会分配较少的计算资源;而在预测句子的第一个单词或者一个单词的首字母时,由于不确定性较高,系统会投入更多的计算力量。
这种智能化的资源分配方式,使得 BLT 能够在给定的算力预算内实现更好的性能。
研究团队得到的实验结果令人振奋。在规模从 4 亿到 80 亿参数的模型测试中,BLT 展现出了卓越的性能。
特别值得一提的是,在控制计算资源使用量的情况下,BLT 能够媲美 Llama 3(甚至是 3.1)的性能表现,同时在推理阶段节省高达 50% 的计算量。
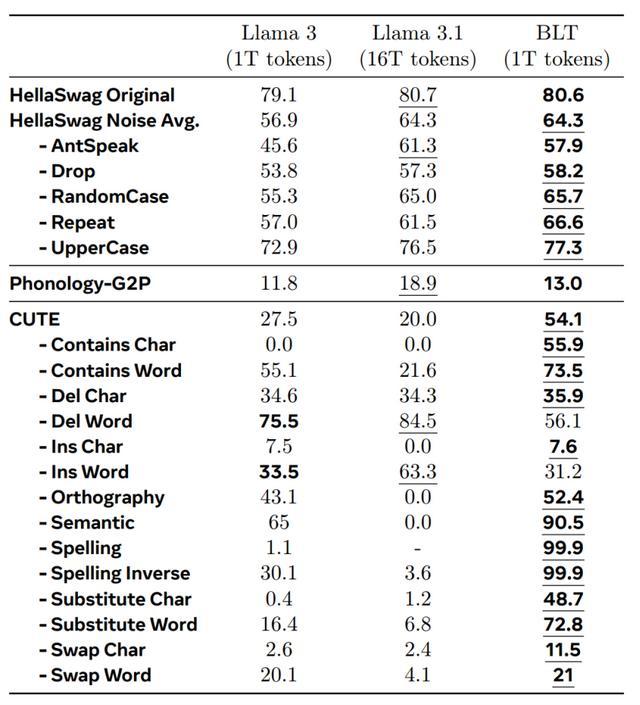
图 | 模型性能对比(来源:Meta)
这种高效率得益于其动态数据块划分机制,让模型能够将节省下来的计算资源用于扩展全局潜在 Transformer 的规模。
更令人惊喜的是,BLT 在处理长尾数据(即训练数据中很少出现的规律)时表现出色。
它能够更好地处理不规则文本、多语言翻译,以及需要字符级理解的任务。
这种能力在处理小语种翻译和编程代码等特殊场景时特别有价值,就像一个博学多才的语言学家,无论遇到多么罕见的语言用法,都能从容应对。
研究人员还发现,在多语言处理方面,BLT 也展现出了独特的优势。
传统的基于 token 的模型在处理网络上代表性较少的语言时,往往会遇到困难,因为这些语言的词汇可能并未被收录在模型的词汇表中。
而由于 BLT 是直接处理字节数据,因此能够更好地适应不同语言的特点,无需事先定义特定语言的词汇表。这一特性使得 BLT 在跨语言应用场景中,具有天然的优势。
不过值得注意的是,这项技术仍处于发展初期。现有的 Transformer 库和代码库都是为传统的基于 token 的架构优化的,这意味着 BLT 还有很大的优化空间。
与其他新技术一样,它需要时间来完善和适应实际应用环境。研究人员们正在探索如何通过软件和硬件优化,来进一步提升 BLT 的性能。
事实上,这并不是 Meta 第一次尝试突破传统 tokenization 方式的限制。
早在 2023 年 5 月,该公司就发布了名为 MegaByte 的类似技术,只是灵活性略逊于 BLT。
著名 AI 开发者安德烈·卡帕西(Andrej Karpathy)也曾指出,摆脱 tokenizers 的限制是推进语言模型发展的重要目标之一。
虽然这些方法目前还未得到广泛采用,但它们都为 AI 语言模型的发展指出了新的方向。
研究人员认为,BLT 的出现不仅解决了当前模型在处理单个字符时的困难,还为处理多样化数据类型提供了更灵活的方案。
随着人们对适应性强、高效率 AI 系统的需求不断增长,BLT 的创新理念很可能会为自然语言处理领域带来新的突破。
就像人类学习语言时既要掌握单词和语法,也要理解字母和发音一样,只有让 AI 模型也具备这种从微观到宏观的全方位理解能力,才能在真正意义上实现与人类的自然交流。
参考资料:
1.https://doi.org/10.48550/arXiv.2412.09871
https://ai.meta.com/research/publications/byte-latent-transformer-patches-scale-better-than-tokens/
https://www.marktechpost.com/2024/12/13/meta-ai-introduces-byte-latent-transformer-blt-a-tokenizer-free-model-that-scales-efficiently/
https://venturebeat.com/ai/metas-new-blt-architecture-replaces-tokens-to-make-llms-more-efficient-and-versatile/
排版:刘雅坤股票短线杠杆怎么操作